我发现一个秘密富才配资,
内存缩水了,不然怎么解释几年前绰绰有余的512G现在连我半台电脑都装不下。
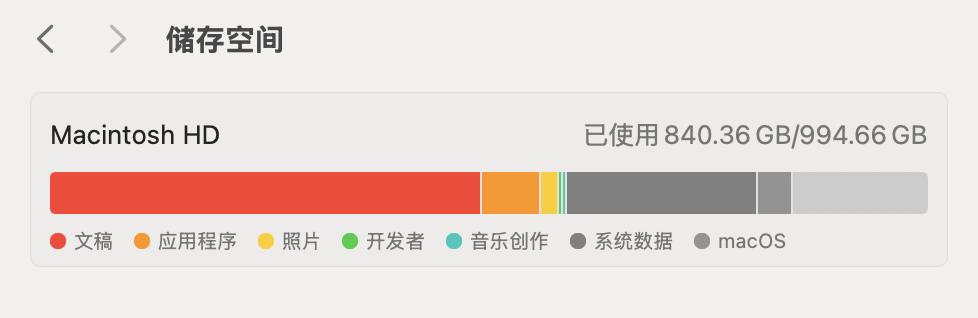
点开存储空间看了一眼,红色几乎要溢出屏幕。仔细一看,陈年的课件,视频、音频、PDF,塞满了每一个角落。它们像一群沉默的幽灵,盘踞在我的硬盘里,每一个文件的名字都承载着我当下下载时的美好期望,
一个我总有一天会去学习的技能。
这种焦虑感迅速蔓延。iCloud也发来了通知,2个T的云空间岌岌可危。打开用了多年的云盘,情况同样惨烈。
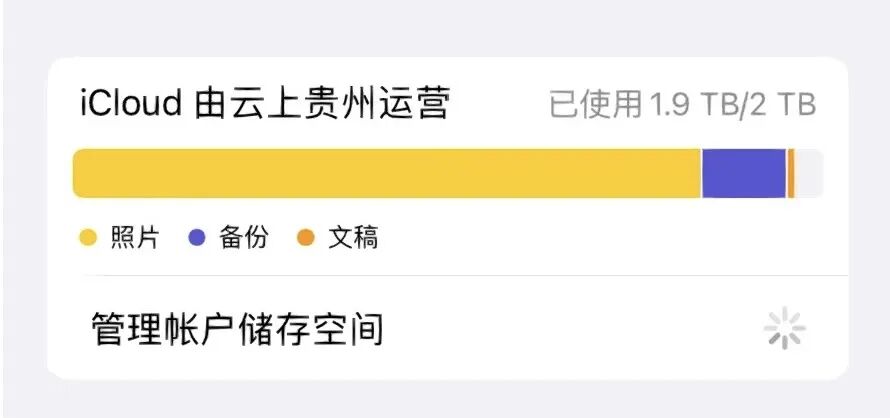
我甚至不敢去算这些资料的总大小,感觉这些其实都代表着我曾经为知识付出的热情,也代表着我永远也追不上的学习进度。我舍不得删,但也没时间和精力去整理。
就在我被这种数字困境折磨到想买个5T移动硬盘来逃避现实的时候,
刚好这几天在云栖大会忙着测阿里那6个新模型,机智的我想到了机智的Qwen3-Omni新用法。
长话短说,
Omni,一个拉丁词,意思是全能,
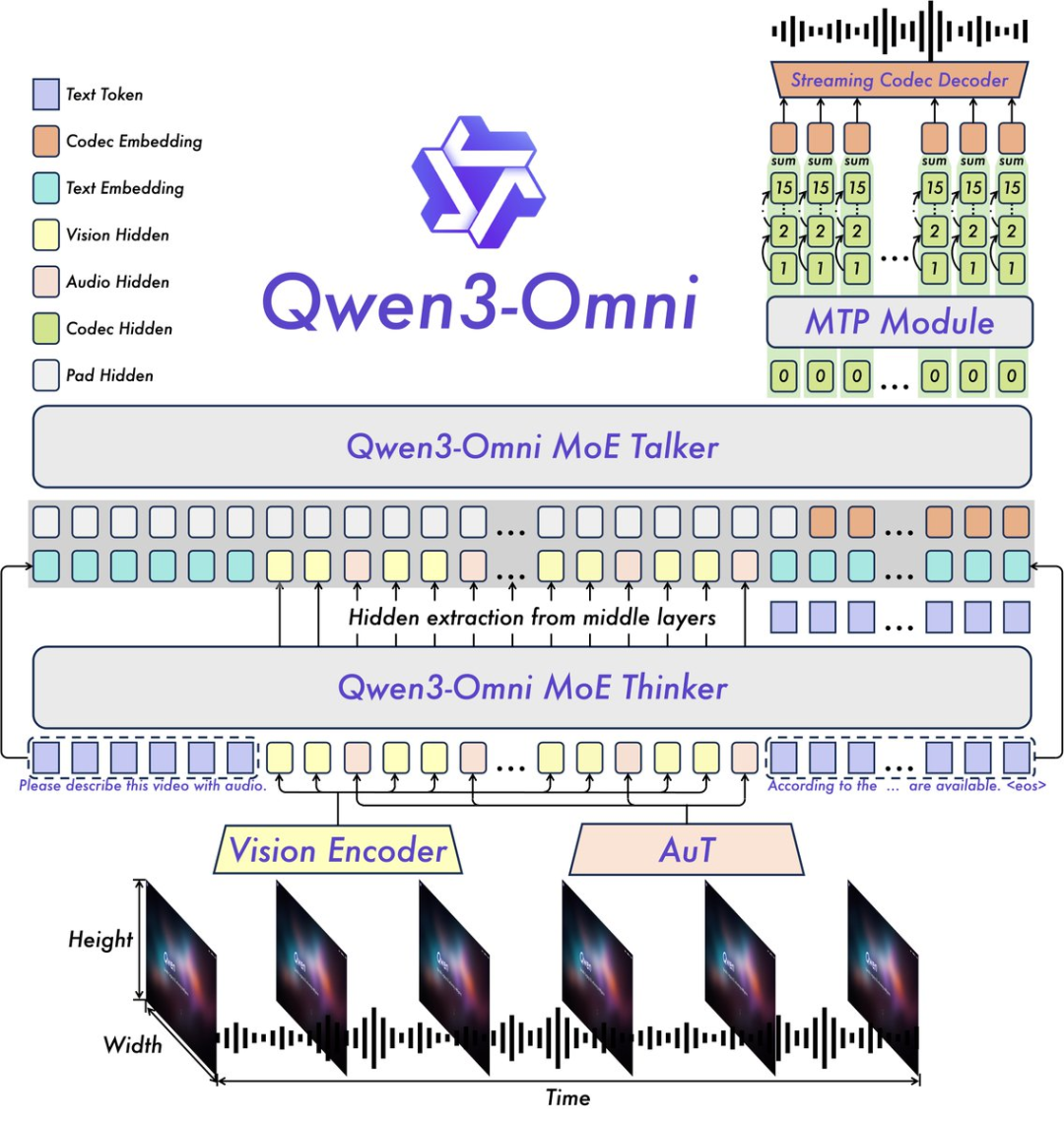
Qwen3-Omni定位就是一个原生端到端全模态 AI,将文本、图像、音频和视频统一在一个模型中,支持文本、图像、音频、视频输入,然后可以输出音频和文本。
https://chat.qwen.ai/
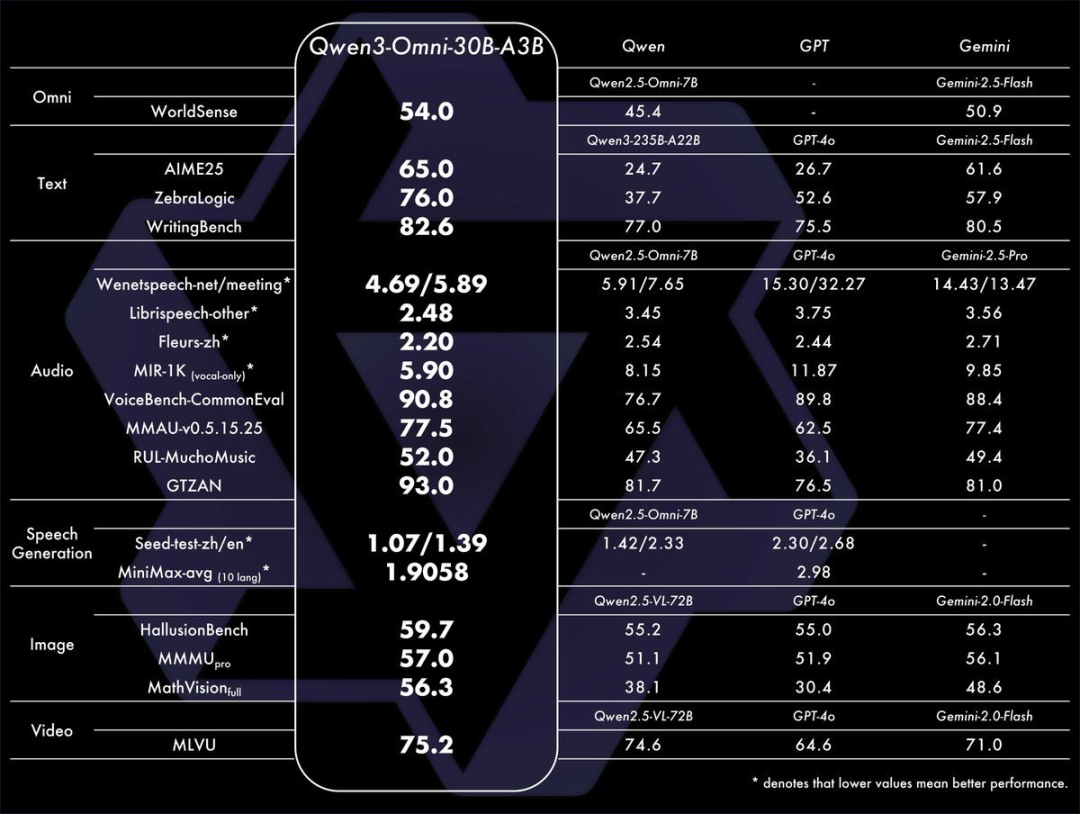
看了一圈技术报告找亮点,这次它的ASR(自动语音识别)、音频理解和语音对话方面达到了与 Google Gemini 2.5 Pro 同级别的性能。
平时一个小时的音频或者视频,我可能需要花几个小时去反复听,去记笔记。这个过程的效率之低,是导致我云盘里堆满课件的根本原因。而Qwen3-Omni就像是给我们装上了一个可以百倍速播放并能自动消化的超级眼睛和超级耳朵。
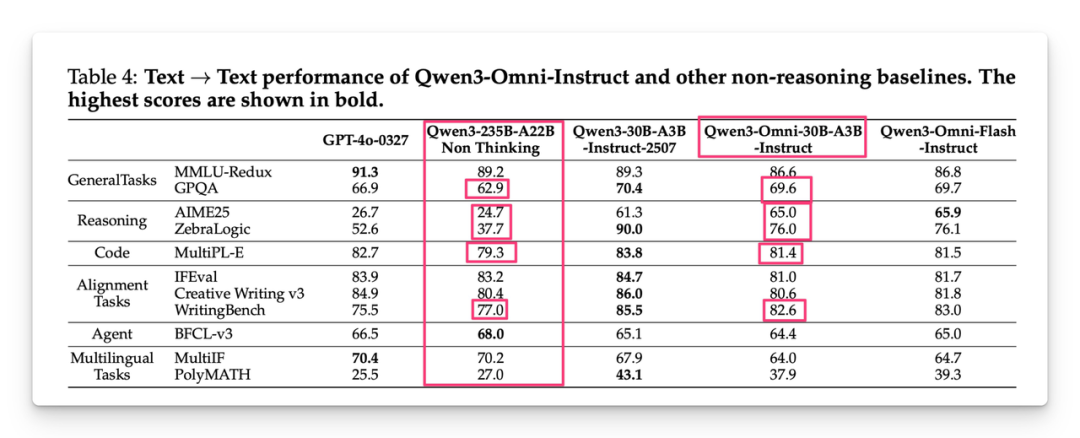
它在实现这种强大能力的同时,并没有陷入参数竞赛的疯狂。Qwen3-Omni这次参数是30B,在考验逻辑推理的GPQA和AIME25,考验思维链能力的ZebraLogic,以及考验写作能力的WritingBench上,参数小了还不降智富才配资,表现超越了他们自己之前发布的千亿级参数的大模型Qwen3-235B-A22B。
我从云盘里翻出了一个尘封已久的文件夹,里面是一门程序员基础算法的视频课程,2019年的,一共十几个G,
压箱底的宝贝(苦笑)
从某鱼19.9收回来后,我只点开过两次,每次都被它冗长的节奏劝退。我把其中一个 01字符串高频面试题精讲 视频下载下来,一起丢给了Qwen3-Omni。
我还有一个超好用的提示语,本来是在NotebookLM用,
现在通过Qwen3-Omni在国内也能用上了,
你将把一段视频重写成\"阅读版本\",按内容主题分成若干小节;目标是让读者通过阅读就能完整理解视频讲了什么,就好像是在读一篇 Blog 版的文章一样。
输出要求:
1. Metadata- Title- Author- URL1. 元数据- 标题- 作者- 网址
2. Overview用一段话点明视频的核心论题与结论。
3. 按照主题来梳理- 每个小节都需要根据视频中的内容详细展开,让我不需要再二次查看视频了解详情,每个小节不少于 500 字。- 若出现方法/框架/流程,将其重写为条理清晰的步骤或段落。- 若有关键数字、定义、原话,请如实保留核心词,并在括号内补充注释。
4. 框架 & 心智模型(Framework & Mindset)可以从视频中抽象出什么 framework & mindset,将其重写为条理清晰的步骤或段落,每个 framework & mindset 不少于 500 字。
风格与限制:- 永远不要高度浓缩!- 不新增事实;若出现含混表述,请保持原意并注明不确定性。- 专有名词保留原文,并在括号给出中文释义(若转录中出现或能直译)。- 要求类的问题不用体现出来(例如 > 500 字)。- 避免一个段落的内容过多,可以拆解成多个逻辑段落(使用 bullet points)。
屏幕上开始飞速滚动输出的文字,不再是那种生硬的、流水账式的记录。
真的如果是那种一句话草草总结的临时笔记我真的建议少用,甚至不要用,这种笔记记多了就会跟我滴答一样,一天居然有300个累积下来的todo,根本不现实富才配资,根本做不完。
Qwen3-Omni给出了摘要,抓住了老师在课程中反复强调的观点,并且用非常清晰的逻辑结构,把它们组织了起来。对于视频中提到的字符串、面试题总体分析(概念理解、规则判断、数字运算、排序与交换、动态规划、搜索等)都有了。

还把核心的解题框架总结出来了,让我可以直接开始用。

整个过程不到两分钟。一个视频就被炼化成了一份5000字、干货满满的文档。
我看着那份条理清晰的笔记,感觉这两小时的知识,已经被我消化了90%,剩下的10%已经不值得我再存6年了,我毫不犹豫地把那个巨大的视频文件,拖进了回收站。
那一刻的感觉,如释重负。
尝到甜头之后,我把目光投向了另一个老大难,叫极客空间的App。我在上面买过不少课,下载到本地也占了不少空间,大部分是音频加图文的形式。这些课质量很高,但我需要一边听着音频,一边在手机的屏幕上划拉,去看那些关键的架构图。我决定让Qwen3-Omni接着挑战这个任务。
我选了一门推荐系统的老课,把其中一节课的音频,和我截下的几张核心图片,一起交给了它。
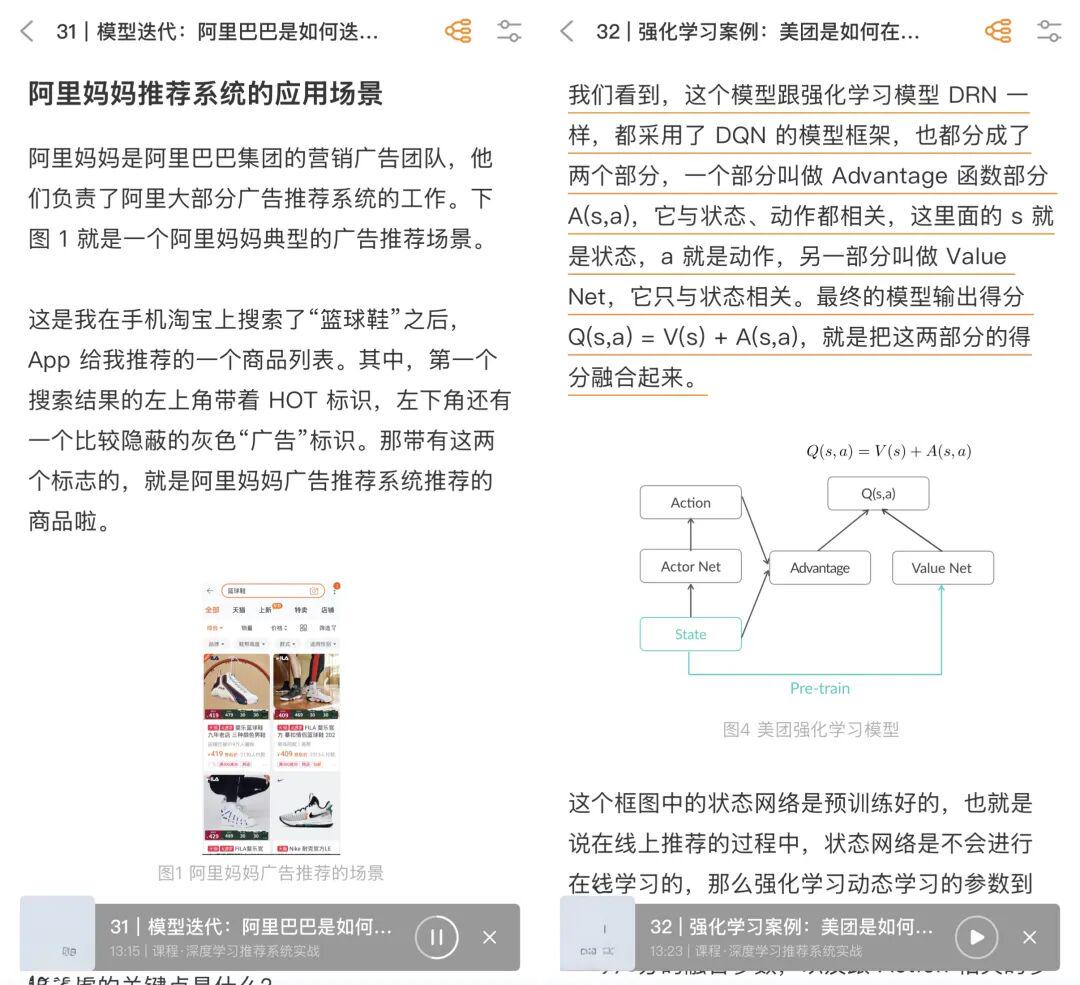
这个任务要求模型不仅能听懂,还要能看懂,更要能将两种不同模态的信息进行关联和理解。
我看到模型首先快速地把音频转化成了文字,准确率一如既往的高。
接着,在输出的笔记里,它会在讲述到某个关键节点时,主动提示我,此处的逻辑可以参考图片一。然后解读了图片一里例题,甚至识别出了图片里的英文术语,并给出了中文解释。

冷知识,Qwen3-Omni实际上是一个模型家族,里面有好几个各司其职的专家。
比如我这次体验的核心,就是Qwen3-Omni-30B-A3B-Instruct。你可以把它理解为全,它既有负责深度思考的大脑,也有负责清晰表达的嘴巴,能够接收视频、音频和文本的输入,然后用文本或者语音交流。
而当遇到特别烧脑的复杂推理任务时,一个更专注的专家Qwen3-Omni-30B-A3B-Thinking就会登场。它同样能理解各种模态的信息,把部份精力都投入到了思维链的推理中,但它只写不说。
还有一位听觉大师,Qwen3-Omni-30B-A3B-Captioner。它能够为任意的音频输入生成详细的描述。
模型更新,总是以一种我意想不到的方式,
帮解决我生活中的具体问题。
一年前用AI看图片都是老大难,现在一小时视频丢进去要翻不出大水花,
困扰我许久的数字存储焦虑,最终会被Qwen3-Omni缓解。
它没有给我无限的硬盘空间,却给了我一种从信息的海洋中提炼知识的全新能力。
也许之后我们有的不再是海量的文件,也不是越买价位越高的存储套餐,
而是经过萃取和消化的、轻量、去重、有统一知识架构的,真正属于我们自己肚子的知识。
而那些曾经压得我喘不过气的数字负担,
早该随风飘散了。
@ 作者 / 卡尔
最后,感谢你看到这里如果喜欢这篇文章,不妨顺手给我们点赞|在看|转发|评论
如果想要第一时间收到推送,不妨给我个星标
更多的内容正在不断填坑中……

鸿岳资本配资提示:文章来自网络,不代表本站观点。
相关文章



沪深京指数
热点资讯
